Understanding the EAV data model and when to use it
One problem many developers encounter while defining and analysing data requirements is the situation where a number of different attributes can be used to describe an object, but only few attributes actually apply to each one.
One option is to create a table with a column representing each attribute; this is suitable for objects with a fixed number of attributes, where all or most attributes have values for a most objects. However, in our case we would end up with records where majority of columns would be empty, because attributes may be unknown or inapplicable.
To solve the above problem you can apply the EAV (Entity, Attribute, Value) model. This pattern is also known under several alternative names including 'object-attribute-value' model and 'open schema'.
In the EAV data model only non-empty values are stored in database, where each attribute-value (or key-value) pair describes one attribute of a given entity. EAV tables are often characterised as 'long and skinny' where 'long' refers to multiple rows describing entity, and 'skinny' refers to the small number of columns used.
In this article we will explore the EAV model and its implementation, and show real-world applications – including a look at how Magento makes use of this pattern.
First some quick notes...
Object attributes are stored in a table with three columns: entity, attribute and value. The entity represents data item being described, for instance a product or a car.
The attribute represents data that describes an entity, for instance a product will have a price, weight and many more characteristics.
The value is the value of that attribute, for example our product might have an attribute price of £9.99. Additionally values can be segregated based on data type, so there would be separate EAV tables for strings, integer numbers, dates, and long text. Splitting the types is done to help support indexing and let the database perform type validation checks where possible.
Sparseness of attributes
In maths and computer science, if an object only has a few attributes from a potentially large number, we call that a 'sparse matrix'. When we talk about the EAV model, we use the term 'sparse' to describe attributes where most have no value.
To illustrate this, let's look at a receipt from a supermarket. The supermarket has thousands of products in stock, with new ones being introduced on daily basis and others withdrawn from sale.
When a customer buys five products the receipt only lists details of items actually purchased – one product per row. The receipt does not list every product in the store that customer could have purchased, so we say the customer's receipt is sparse.
In database terms the entity is the sales receipt, with information such as transaction id, date and time, store location, etc. Each detailed line in the receipt corresponds to a record in the sales line table, and stores an attribute plus one or more values.
In this scenario an attribute is a product purchased by the customer. The values are quantity, unit price, discount, and total price.
The above example illustrates the sparseness of attributes (a customer buys only a selection of the available products) and introduces us to a new term: row modelling. The table is row modelled where the series of facts describing an entity are recorded as multiple rows. Every new set of facts is stored in database as additional rows rather than additional columns.
Row modelling is a standard data modelling technique in designing databases. It should only be used where following two conditions are met:
- the data for a particular entity is sparse
- the data is vulnerable to change
Row modelling is inappropriate where sparseness and volatility don't exist, in such case traditional column modelling should be used.
Example of row modelling
In this example we have three entities: Product, Customer and Invoice. Both Products and Customers are standard relational tables.
As mentioned earlier in this article, there are two conditions that need to be met for row modelling to be a good choice; the data for a particular entity is sparse, and it is vulnerable to change
We know that products are constantly fluctuating with new being introduced and old withdrawn. At the same time, the invoice table cannot have a column for each product as this would be impractical.
The invoice table contains main information about the event of sale; the customer, the date and the time, and the invoice id. Each invoice is then described by rows recorded in the invoice_lines table. Each row specifies which product was purchased, the price per unit, and the quantity.
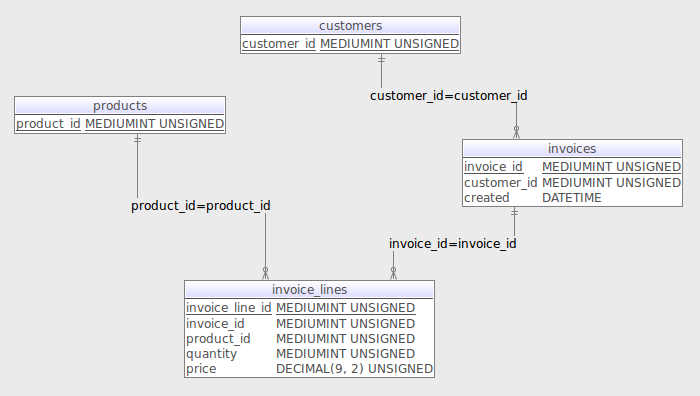
EAV vs row modelling
Entity-Attribute-Value design is a generalisation of row modelling. It means that all types of facts are recorded in a single table across the entire database, where a row-modelled table is homogeneous in the facts that it describes. Moreover, the data type of a value column in a row-modelled table is pre-determined, whereas in an EAV table, a value's data type depends on a attribute recorded in a particular row.
It can be difficult to choose the best approach for modelling data, but as a guideline you would consider EAV modelling over row modelling when:
- Individual attributes are different in data types recorded (Yes/No, numerical values, strings). It makes storing attribute values in one table difficult when row modelling is used.
- Numerous categories of data need to be represented, and their number can fluctuate. At the same time categories have very small number of instances, even if the attributes are not sparse. Use of conventional modelling in such case would mean hundreds of tables with very few rows.
- In certain types of environments, where categories/classes need to be created on the fly and some classes are often eliminated in subsequent cycles of prototyping.
- Where there are categories classed as hybrid, meaning that some class attributes are non-spares and other attributes are highly sparse. In this situation the non-sparse attributes are stored in conventional table, while the sparse attributes are stored in EAV or row-modelled format. The classes are commonly met in business database application, where descriptions of products depends on product category, but all products will share attributes such as packaging unit and cost per item. Note that if there are only one or two hybrid classes, the EAV design may not be worthwhile.
Representing entities, attributes and values
Representing Entities
An entity can be any item, so far we have seen examples where an entity was an event of sale, a merchant and a product. Entities in EAV are managed via an Objects table that captures common facts about each item, such as name, description, and so on. The Objects table must have unique identifier for each entity, and this is usually automatically generated. The identifier is then used across the database as a foreign key.
Using EAV modelling does not stop us from using conventional tables to capture additional details for individual objects. It is common to employ traditional relational database modelling and EAV modelling approaches within the same database schema.
Representing Attributes
Attributes are stored in a dedicated attributes table. The primary key of this table is used as a reference across the database. The attributes table is usually supplemented with multiple metadata tables that describe an attribute in further detail. This metadata information is often used to automate generation of user interfaces for browsing and editing data. The metadata tables would be likely to contain some of the following types of information:
- Validation: Validation metadata includes data type of an attribute, default value, limits a number of possible values and whether the value can be null.
- Presentation: Defines how attribute is presented to a user, whether it is text area, drop down or set of radio buttons / check boxes.
- Grouping: Attributes are mostly presented in groups to a user. Grouping metadata defines an order in which attribute is displayed, number of attributes presented and what type of font or colour is used.
- >Range of normal values: In some situations ranges of normal values are also stored. They may vary based of sex, age, etc.
Representing Values
The simplest solution to represent data in an EAV model is to store it as a string. However, this approach is relatively inefficient since it requires data type conversions when doing anything with values. Additionally, indexes on values stored as strings do not allow optimised range searches for numeric and date types; this is a common problem when working with key-value pairs data of mixed data types.
To improve on this situation, the EAV model uses separate tables for each data type. Attribute metadata identifies the correct data type and subsequently the EAV table in which data is stored. This approach is much more efficient as it allows metadata caching for a given set of attributes in a form prior to accessing the data.
One major drawback of this solution is seen when the data type of an attribute needs changing. This requires reassigning data from one table to another, which is inconvenient, and can be done using stored procedures.
In general, values that are empty or do not apply to this entity are not stored in the EAV model. In some circumstances however there is a need to record reasons for missing values. In such cases the solution is to add a missing value code column to a table, which is non-null only when the value column is null. This code is then used to look up a list of textual explanations.
An EAV example
The simplest implementation of EAV may have just three tables: entity, attribute and value. An example of this setup is shown here:
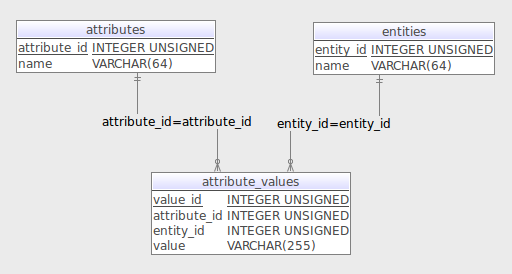
However, in such implementation we lose metadata information and all the values are stored as varchar, regardless of their data type. As a variation on this approach, we can alternatively implement a strongly-typed approach where a value of given data type is recorded in a table specific to that data type. An example schema is shown below and includes the metadata storage that we covered earlier.
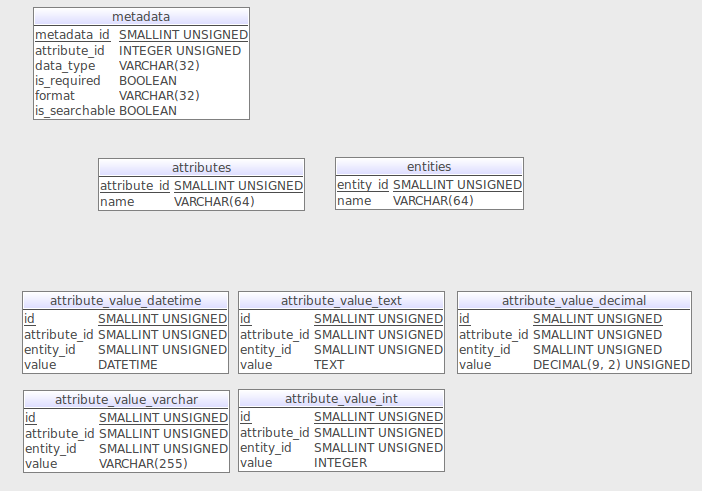
How Magento uses the EAV model
In open source and php community one of the most well-known implementations of the EAV model is in Magento, the e-commerce platform. Let us begin by taking a look at the Magento database schema. Although this may appear complicated at first, we will look at it in stages.
As mentioned before an entity can be any item or event. In Magento there are multiple entities, for instance: customer, order, invoice and product. For the purpose of this article I will use product entity to explain EAV implementation. The main table for products is catalog_product_entity. However, you may be surprised that it only holds a few pieces of information, such as entity type, SKU and when product was created.
In order to build an entire product record we need to find its attributes and then find a value for each of the attributes. In catalog_product_entity you will find the entity_type_id column. This is used across the entire database as the entity type identifier. Based on the entity type we can find which attributes are assigned to a product by looking in eav_attribute.
This table records all attributes for all entities within Magento. It also has metadata information for each record, such as data type, front end details, etc. For products, entity type id is set to 4 (types are listed in the eav_entity_type table). Toselect all the attributes that are assigned to products, we simply do:
SELECT * FROM eav_attribute WHERE entity_type_id = 4;The name of an attribute is recorded as attribute_code; from the metadata information, an important column is backend_type. This indicates what data type an attribute is and where the values for the attribute are stored. Magento allows following data types:
- static
- datetime
- decimal
- int
- text
- varchar
As mentioned before values can be stored in multiple tables based on their types. To examine a particular attribute, we could use a query like this:
SELECT * FROM eav_attribute WHERE entity_type_id = 4 AND attribute_code = 'name';After running above query we can see that attribute 'name' has a data type of varchar. The product attributes values are stored across a number of tables: catalog_product_entity_datetime, catalog_product_entity_decimal, catalog_product_entity_int, catalog_product_entity_text, catalog_product_entity_varchar. These table names illustrate the way different data types are stored in the EAV model.
To get a list of all products and their names we can use a query like this:
SELECT cpe.entity_id, value AS name FROM catalog_product_entity cpe
INNER JOIN eav_attribute ea ON cpe.entity_type_id = ea.entity_type_id
INNER JOIN catalog_product_entity_varchar cpev ON ea.attribute_id = cpev.attribute_id AND cpe.entity_id = cpev.entity_id
WHERE ea.attribute_code = 'name'The concept is simple once you know where to start and how to find the next table in hierarchy. All the other entities follow the same principle: you find entity type id for an object you are interested in, then you get all attributes from eav_attribute based on it and finally select values for each attribute from different tables based on attribute type.
Advantages and disadvantages of the EAV model
The main advantage of using EAV is its flexibility. Table holding attributes describing an entity is not limited to a specific number of columns, meaning that it doesn't require a schema redesign every time new attribute needs to be introduced. The number of attributes can grow vertically (new table record for every new parameter) as the database evolves, without the need for structure changes.
The fact that EAV handles only non-empty attributes means that there's no need to reserve additional storage space for attributes whose values would be null. This makes the EAV model quite space efficient.
Physical data format is very clean and is similar to XML, allowing data to be easily mapped to XML format; it only requires replacing the attribute name with start-attribute and end-attribute tags.
EAV model is excellent for rapidly evolving applications because it protects us against consequences of constant change. We can simply record new data of any structure without the need to modify the database schema.
When considering EAV it is important to identify whether the data is sparse and numerous since the complexity of EAV design exceeds its advantages when used for inappropriate data set. It would be more appropriate to opt for conventional tables for schemas that are relatively static and/or simple.
A major downside of EAV is its lower efficiency when retrieving data in bulk in comparison to conventional structure. In EAV model the entity data is more fragmented and so selecting an entire entity record requires multiple table joins. What is more, when working with large volumes of EAV data, it can be necessary to transiently or permanently convert between columnar and row/EAV -modelled representation of the same set of data. The operation can be error-prone and CPU intensive.
Another limitation of EAV is the fact that we need additional logic in place to complete tasks that would be done automatically by conventional schemas. However, existing EAV tools can be implemented to reduce the overheads of this.
Finally, understanding the EAV model does require time. It has a definite learning curve, so junior developers may struggle working with this model, before they can truly understand the concept.
Conclusion
The Entity Attribute Value should be considered if the following conditions are met:
- Data are sparse and heterogeneous, with wide range of attributes that can apply to an entity and new attributes being often introduced.
- The number of classes is very large, with classes having numerous instances, even if the attributes are not sparse.
- There are numerous hybrid classes, possessing both sparse and non-sparse attributes. Typically, not all classes in the data will meet the requirements for EAV modelling.
In production, schemas tend to be mixed, including conventional relational, EAV or hybrid approaches as appropriate. The EAV modelling, however, requires introduction of metadata to capture the logical model data for EAV. We saw that in Magento this is used to great effect where the various different products will have very different attributes set; a nice illustration of where this model can be applied very effectively.
This post has hopefully shown you what the EAV model is and how, and more importantly when, to use it!


